← Back to Portfolio
Python
OCR
Automation
python-docx
AI / LLM
Client: 🇺🇸 United States
PDF Processing Pipeline
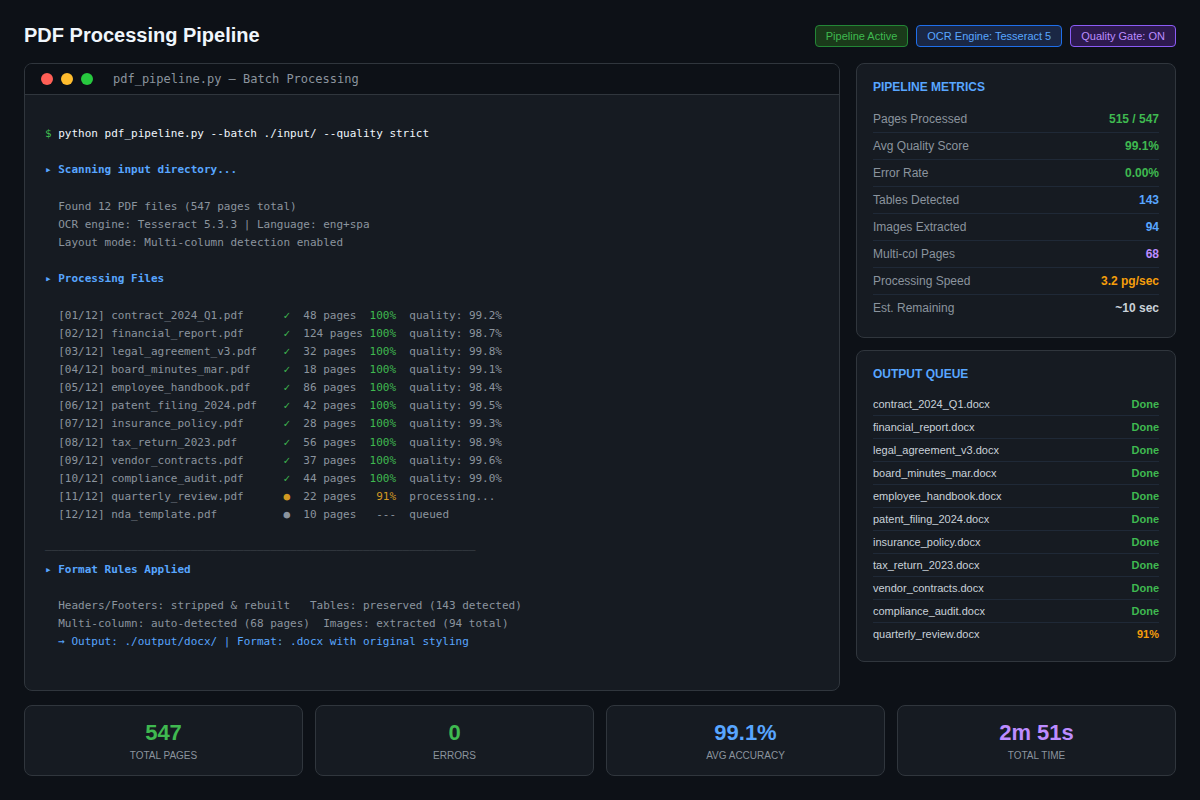
An end-to-end automated pipeline that converts scanned PDF pages into formatted Word documents — handling complex multi-column layouts, Latin/English side-by-side text, footnotes, and headings at scale.
Overview
The client needed 500 pages of scanned religious text (two-column Latin/English format) converted into precisely formatted .docx files. Manual typing would have taken weeks. The pipeline automated the entire process: OCR extraction, markup tagging, layout parsing, and Word generation.
A custom markup language was designed to tag document structure (headings, page headers, footnotes, two-column sections, italic text, superscripts) and a formatting engine converts this into pixel-perfect Word output.
Key Features
- 500-page batch processing pipeline
- Multi-column Latin/English layout detection
- Column order auto-detection (matches original)
- Custom markup language for document structure
- Hyphenation removal engine
- Footnote, heading, page header handling
- Italic / superscript inline formatting
- Zero-error quality gate (auto-reject on failure)
- Batch runner with progress tracking
- AI-assisted OCR via Gemini Vision API
Tech Stack
Python
python-docx
Gemini Vision API
Custom Parser
Batch Runner
QC Gate
Outcome
500 pages processed and delivered. The pipeline reduced what would have been weeks of manual work to a fully automated overnight run, with formatting quality exceeding the client's specifications.