クライアント: 🇺🇸 アメリカ
PDF Processing Pipeline
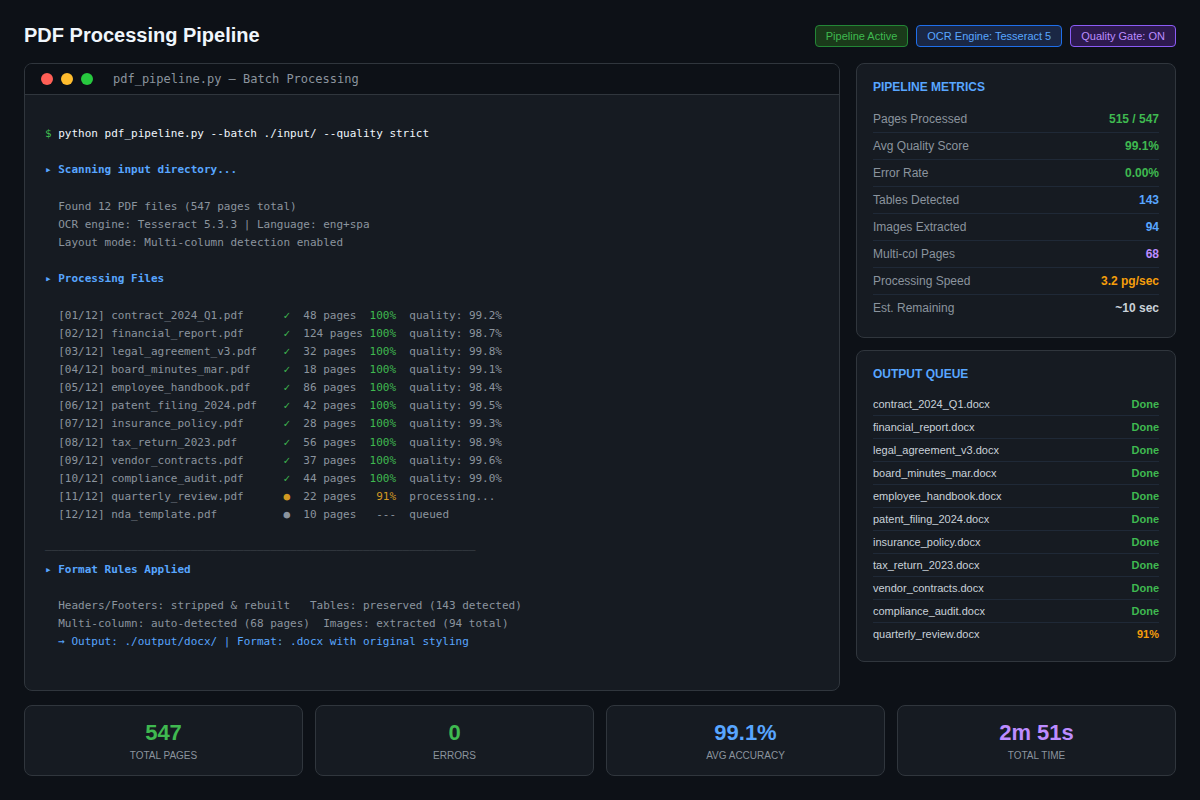
スキャンPDFページをフォーマット済みWord文書に変換するエンドツーエンドの自動パイプライン。複雑な多段組レイアウト、ラテン語/英語の並列テキスト、脚注、見出しを大量に処理。
スキャンPDFページをフォーマット済みWord文書に変換するエンドツーエンドの自動パイプライン。複雑な多段組レイアウト、ラテン語/英語の並列テキスト、脚注、見出しを大量に処理。
クライアントが必要としていたのは、500ページにわたるスキャン済み宗教テキスト(ラテン語/英語の2段組形式)を精密にフォーマットされた.docxファイルに変換すること。手作業での入力では数週間を要する作業でした。このパイプラインはOCR抽出、マークアップタグ付け、レイアウト解析、Word生成の全工程を自動化しました。
文書構造(見出し、ページヘッダー、脚注、2段組セクション、斜体テキスト、上付き文字)をタグ付けするカスタムマークアップ言語を設計し、フォーマットエンジンがこれをピクセルパーフェクトなWord出力に変換します。
500ページを処理・納品完了。数週間かかる手作業を完全自動化されたオーバーナイト処理に短縮し、フォーマット品質はクライアントの仕様を上回りました。